Системи електронного перекладу текстів, системи електронного розпізнавання текстів. Програми Adobe Reader, DjVu Reader.
Щоб знайти переклад невідомого іноземного слова, користувачеві електронного словника достатньо ввести це слово в рядку пошуку, і вже за мить буде отриманий переклад.
Сучасні текстові процесори мають у своєму складі словники, що дозволяють виробляти орфографічну перевірку правильності написання слів (на різних мовах).
Розглянемо простий приклад. Переведемо за допомогою системи перекладу на англійську мову фразу:
Інформатика - це наука про інформацію.
Результат перекладу:
The computer science is an information science.
А тепер за допомогою тієї ж програми переведемо цю фразу на українську мову.
Автоматичне розпізнавання текстів
Після опрацювання документа сканером виходить графічне зображення документа (графічний образ). Але графічний образ ще є текстовим документом. Людині досить подивитися аркуш паперу з текстом, аби зрозуміти, що вона написано. З погляду комп'ютера, документ після сканування перетворюється на набір різнобарвних точок, а не в текстовий документ.
Проблема розпізнавання тексту у складі точечної графічного зображення є дуже складним. Такі завдання вирішують за допомогою спеціальних програмних засобів, званих засобами розпізнавання образів. Реальний технічний прорив у цій галузі стався лише останні роки..
Програми розпізнавання текстів
Оскільки потреба у розпізнаванні тексту відсканированих документів досить велика, не дивно, що є дуже багато програм, для цього. Ми зупинимося на програмі FineReader, яка забезпечує високу якість розпізнавання і зручність застосування.
Програма FineReader
Програма FineReader випускається російської компанією ABBYY Software (www.bitsoft.ru). Ця програма варта розпізнавання текстів російською, англійському, німецькому, українському, французькому і багатьох іншими мовами, і навіть для розпізнавання змішаних двомовних текстів.
Програма має низку зручних можливостей. Вона дозволяє об'єднувати сканування розпізнавання до однієї операцію, працювати з пакетами документів (чи з многостраничными документами) і з бланками. Програму можна навчати підвищення якості розпізнавання невдало надрукованих текстів чи складних шрифтів. Вона дозволяє редагувати розпізнаний і перевіряти його орфографію.
Вікно програми
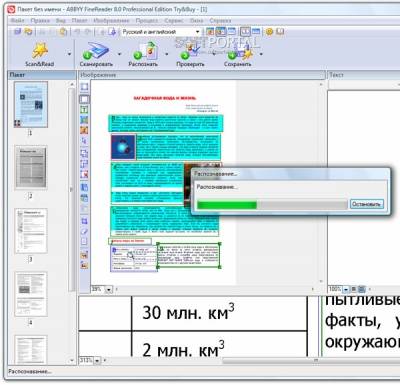
У лівій частини робочої області розташовується панель «Пакет», яка містить список графічних документів, що їх перетворено на текст. Ці графічні файли розглядаються як частини одного документа. Результати їх опрацювання надалі об'єднують у єдиний текстовий файл. Форма значка, що відзначає вихідні файли, вказує, було вироблено розпізнавання.
Панель у нижній частині робочої області містить фрагмент графічного документа в збільшеному вигляді. З її допомогою можна оцінити якість розпізнавання.
Решту робочої області займають вікна документів. Тут розташовується вікно графічного документа, що підлягає розпізнаванню, і навіть вікно текстового документа, отриманого після розпізнавання.
У верхню частину вікна додатка за рядком меню розташовуються панелі інструментів. На наведеному малюнку включено відображення всіх панелей, які можуть використовуватися у програмі FineReader.
Панель інструментів «Стандартна» містить кнопки відкриття документів.
Панель «Scan&Read» містить кнопки, що відповідають усім етапам перетворення паперового документа в електронний текст. Перша кнопка дозволяє виконати таке перетворення на межах єдиної операції.
Панель «Розпізнавання» дозволяє вказати мову документу й вид шрифту.
Параметри сканування
Якість розпізнавання залежить від якості сканованого зображення.
Після установки програми FineReader в меню «Програми» Головного меню з'являються пункти, щоб забезпечити роботу з нею. Вікно програми має типовий для додатків Windows9Х вигляд і містить рядок меню, ряд панелей інструментів, і робочу область.
При створенні електронних бібліотек і архівів шляхом перекладу книг і документів у цифровий комп'ютерний формат, при переході підприємств від паперового до електронного документообігу, при необхідності відредагувати отриманий по факсу документ використовуються системи оптичного розпізнавання символів.
За
допомогою сканера  досить
просто одержати зображення сторінки тексту в графічному файлі. Для одержання
документа у форматі текстового файлу необхідно провести розпізнавання тексту,
тобто перетворити елементи графічного зображення в послідовності текстових
символів.
досить
просто одержати зображення сторінки тексту в графічному файлі. Для одержання
документа у форматі текстового файлу необхідно провести розпізнавання тексту,
тобто перетворити елементи графічного зображення в послідовності текстових
символів.
Спочатку необхідно розпізнати структуру розміщення тексту на сторінці: виділити колонки, таблиці, зображення і так далі. Далі виділені текстові фрагменти графічного зображення сторінки необхідно перетворити в текст.
Якщо вихідний документ має типографську якість (досить великий шрифт, відсутність погано надрукованих символів або виправлень), то завдання розпізнавання вирішується методом порівняння з растровим шаблоном. Спочатку растрове зображення сторінки розділяється на зображення окремих символів. Потім кожний з них послідовно накладається на шаблони символів, наявних у пам'яті системи, і вибирається шаблон з найменшою кількістю відмінних від вхідного зображення крапок.
При розпізнаванні документів з низькою якістю друку (машинописний текст, факс і так далі) використовується метод розпізнавання символів по наявності в них певних структурних елементів (відрізків, кілець, дуг і ін.).
Будь-який символ можна описати через набір значень параметрів, що визначають взаємне розташування його елементів. Наприклад, буква «Н» і буква «И» складаються із трьох відрізків, два з яких розташовані паралельно один одному, а третій з'єднує ці відрізки. Відмінність між даними буквами — у величині кутів, які утворює третій відрізок із двома іншими.
При розпізнаванні структурним методом у символьному зображенні виділяються характерні деталі й рівняються зі структурними шаблонами символів. У результаті вибирається той символ, для якого сукупність усіх структурних елементів і їх розташування найбільше відповідає розпізнаваємому символу.
FineReader — система оптичного розпізнавання символів розроблена російською компанією ABBYY Software House.Підтримує розпізнавання тексту на 184 мовах і має вбудовану перевірку орфографії на 38 з них.
Завершення розпізнавання
Розпізнавши сторінки, FineReader запропонує сканувати і розпізнавати далі (якщо сканується книга) чи зберегти текст у формати - від документів Microsoft Office до HTML і PDF.
При розпізнаванні FineReader зберігає усі параметри форматування документу з його графічним оформленням.